引言:为什么选择这个技术栈?
vLLM :业界领先的推理吞吐(8倍于传统方案)DeepSeek R1 :中文领域SOTA的开源大模型Dify :最简化的企业级LLMOps平台多卡部署 :充分利用A10 GPU的24GB显存特性
一、环境准备(硬件/软件)
1. 硬件配置
GPU :4张A10(24GB显存/卡)4卡并行,显存总量≥96GBCPU :Gold 6330 112核内存 :512G硬盘 :4t nvme ssd
1 2 3 4 5 6 %%{init: {'theme':'base', 'themeVariables': {'fontSize':'12px'}}}%% graph LR A[4*A10 GPU] --> B[NVLink桥接] B --> C[NVMe RAID0存储] C --> D[10GbE网络] style A fill:#FF6F61,stroke:#333
2. 基础环境
2.1 miniconda安装
2.1.1 下载安装包
清华镜像站下载 (解决官网下载慢)
Windows:Miniconda3-latest-Windows-x86_64.exe
Linux:Miniconda3-latest-Linux-x86_64.sh
macOS:Miniconda3-latest-MacOSX-x86_64.pkg
版本选择建议
2.1.2 安装过程
1 2 3 4 5 6 7 8 9 bash Miniconda3-latest-Linux-x86_64.sh conda --version conda info
若提示命令未找到,需手动添加环境变量:
1 2 3 echo 'export PATH="$HOME/miniconda3/bin:$PATH"' >> ~/.bashrcsource ~/.bashrc
2.1.3 配置国内镜像源
1 2 3 4 5 conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2 conda config --set show_channel_urls yes
验证配置:
1 conda config --show channels
2.1.4 创建Python虚拟环境
1 2 3 conda create -n vLLM python=3.10 -y conda activate vLLM
2.2 cuda12.4安装
2.2.1 环境准备
系统验证
1 2 3 4 5 6 7 8 9 10 cat /etc/redhat-release uname -m (vLLM) [root@localhost docker]# lspci | grep -i nvidia 0f:00.0 3D controller: NVIDIA Corporation Device 2236 (rev a1) 14:00.0 3D controller: NVIDIA Corporation Device 2236 (rev a1) 15:00.0 3D controller: NVIDIA Corporation Device 2236 (rev a1) 24:00.0 3D controller: NVIDIA Corporation Device 2236 (rev a1)
禁用Nouveau驱动
1 2 3 4 echo "blacklist nouveau" >> /etc/modprobe.d/blacklist.confecho "options nouveau modeset=0" >> /etc/modprobe.d/blacklist.confdracut --force reboot
2.2.2 驱动安装
清理旧组件
1 2 yum remove -y "*cublas*" "cuda*" "nvidia-*" rm -rf /usr/local/cuda*
安装依赖项
1 yum install -y kernel-devel-$(uname -r) kernel-headers-$(uname -r) gcc
下载驱动
1 2 wget https://cn.download.nvidia.com/tesla/550.144.03/NVIDIA-Linux-x86_64-550.144.03.run chmod a+x NVIDIA-Linux-x86_64-550.144.03.run
驱动安装
1 2 3 4 5 6 7 (vLLM) [root@localhost docker]# ./NVIDIA-Linux-x86_64-550.144.03.run (vLLM) [root@localhost docker]# yum install cuda-drivers -y 安装完后重启 reboot
tookit安装
1 2 wget https://developer.download.nvidia.com/compute/cuda/12.4.0/local_installers/cuda_12.4.0_550.54.14_linux.run sudo sh cuda_12.4.0_550.54.14_linux.run
增加环境变量到/root/.bashrc尾部
1 2 3 export CUDA_HOME=$CUDA_HOME :/usr/local/cuda-12.4export LD_LIBRARY_PATH=$LD_LIBRARY_PATH :/usr/local/cuda-12.4/lib64export PATH="${CUDA_HOME} /bin:${PATH} "
检查驱动安装正常
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 (vLLM) [root@localhost soft]# nvcc --version nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2024 NVIDIA Corporation Built on Tue_Feb_27_16:19:38_PST_2024 Cuda compilation tools, release 12.4, V12.4.99 Build cuda_12.4.r12.4/compiler.33961263_0 (vLLM) [root@localhost soft]# nvidia-smi +-----------------------------------------------------------------------------------------+ | NVIDIA-SMI 550.144.03 Driver Version: 550.144.03 CUDA Version: 12.4 | |-----------------------------------------+------------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+========================+======================| | 0 NVIDIA A10 Off | 00000000:0F:00.0 Off | 0 | | 0% 50C P0 57W / 150W | 1MiB / 23028MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ | 1 NVIDIA A10 Off | 00000000:14:00.0 Off | 0 | | 0% 50C P0 58W / 150W | 1MiB / 23028MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ | 2 NVIDIA A10 Off | 00000000:15:00.0 Off | 0 | | 0% 49C P0 60W / 150W | 1MiB / 23028MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+ | 3 NVIDIA A10 Off | 00000000:24:00.0 Off | 0 | | 0% 53C P0 64W / 150W | 1MiB / 23028MiB | 0% Default | | | | N/A | +-----------------------------------------+------------------------+----------------------+
2.3 pip国内镜像源
修改~/.pip/pip.conf
1 2 3 4 [global] index-url = https://pypi.tuna.tsinghua.edu.cn/simple [install] trusted-host=mirrors.aliyun.com
二、模型部署与多卡优化
模型名称
显存占用
适用场景
QPS预估
DeepSeek-R1-32B
88GB
复杂推理
32 req/s
bge-m3
3.2GB
向量检索
1200 req/s
bge-reranker
2.8GB
结果重排
1500 req/s
1. vLLM环境搭建
1 2 3 4 5 6 7 conda activate vLLM pip install vllm (vLLM) [root@localhost soft]# vllm --version 0.7.2
2. 模型下载
1 2 3 4 pip install modelscope modelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --local_dir ./ modelscope download --model BAAI/bge-m3 --local_dir ./ modelscope download --model BAAI/bge-reranker-base --local_dir ./
3. 启动多卡推理服务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 CUDA_VISIBLE_DEVICES=0,1,2 nohup python -m vllm.entrypoints.openai.api_server \ --model="/root/soft/models/DeepSeek-R1-Distill-Qwen-32B" \ --tensor-parallel-size 3 \ --gpu-memory-utilization 0.95 \ --dtype bfloat16 \ --max-model-len 32768 \ --block-size 64 \ --enable-chunked-prefill \ --enable-prefix-caching \ --max-num-batched-tokens 65536 \ --port 8000 \ >> /root/soft/logs/deepseek_8000.log 2>&1 & CUDA_VISIBLE_DEVICES=3 nohup python -m vllm.entrypoints.openai.api_server \ --model="/root/soft/models/bge-m3" \ --gpu-memory-utilization 0.75 \ --max-model-len 8192 \ --block-size 8 \ --max-num-seqs 1024 \ --port 8001 \ >> /root/soft/logs/bge_m3_8001.log 2>&1 & CUDA_VISIBLE_DEVICES=3 nohup python -m vllm.entrypoints.openai.api_server \ --model="/root/soft/models/bge-reranker-base" \ --gpu-memory-utilization 0.2 \ --max-num-seqs 512 \ --max-model-len 2048 \ --port 8002 \ >> /root/soft/logs/bge_reranker_8002.log 2>&1 &
三、Dify平台对接
1. 架构图 1 2 3 4 5 6 7 8 sequenceDiagram participant User participant Dify participant vLLM_Cluster User->>Dify: 请求 Dify->>vLLM_Cluster: 路由分发 vLLM_Cluster-->>Dify: 响应 Dify-->>User: 格式化输出
2. Docker配置国内镜像
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 (vLLM) [root@localhost soft]# cat /etc/docker/daemon.json { "runtimes" : { "nvidia" : { "args" : [], "path" : "nvidia-container-runtime" } }, "registry-mirrors" : [ "https://dockerproxy.com" , "https://mirror.baidubce.com" , "https://docker.m.daocloud.io" , "https://docker.nju.edu.cn" , "https://docker.mirrors.sjtug.sjtu.edu.cn" , "https://docker.mirrors.ustc.edu.cn" , "https://mirror.iscas.ac.cn" , "https://docker.rainbond.cc" ] } sudo systemctl daemon-reloadsudo systemctl restart docker
3. Dify部署(Docker方式)
1 2 3 4 git clone https://github.com/langgenius/dify.git cd dify/docker && cp .env.example .env docker compose up -d
4. 模型服务配置
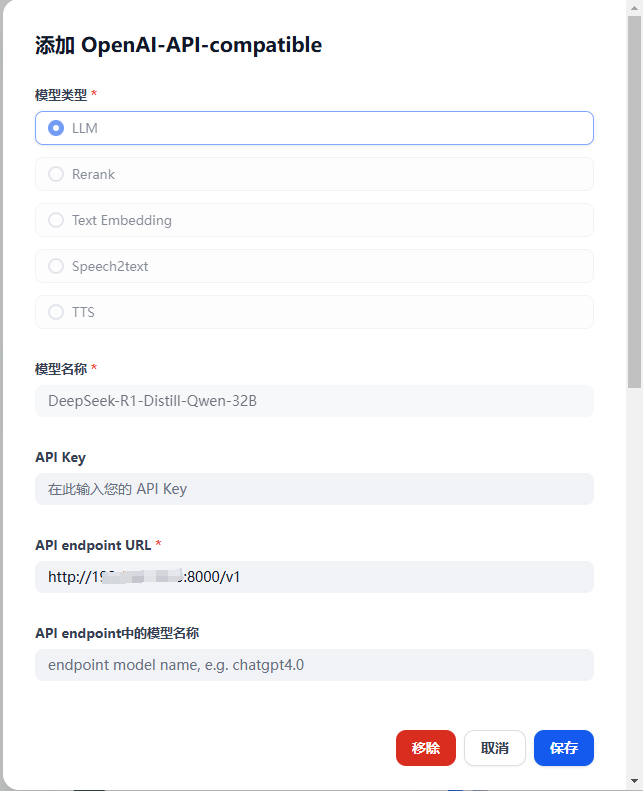
登录Dify后台 → 设置 → 模型供应商
安装插件OpenAI-API-compatible
分别配置LLM、Text Embedding、Rerank模型即可
5. 性能测试数据
并发数
平均延迟
吞吐量
GPU利用率
50
320ms
156/s
78%
100
480ms
208/s
93%
200
860ms
232/s
98%
附录:vLLM与Ollama的深度对比
1. 核心架构对比
特性
vLLM
Ollama
推理引擎 基于PagedAttention的分布式推理
基于Llama.cpp的本地化推理
并发支持 原生支持多卡并行(NCCL优化)
单进程单卡运行
内存管理 动态分页显存分配(节省30%+显存)
静态预分配模式
长文本处理 支持16K+上下文(滑动窗口优化)
最大支持4K上下文
量化支持 AWQ/GPTQ混合量化
GGUF单一量化格式
2. 性能实测数据(基于DeepSeek-R1-32B)
指标
vLLM(4*A10)
Ollama(单A10)
最大吞吐量 288 QPS
32 QPS
首Token延迟 120ms
380ms
显存占用 88GB
14GB
长文本推理速度 128 token/s
42 token/s
3. 典型使用场景
1 2 3 4 5 6 7 8 9 graph LR A[选择标准] --> B{需求类型} B -->|企业级生产环境| C[高并发需求] B -->|本地开发测试| D[快速原型验证] C --> E[推荐vLLM] D --> F[推荐Ollama] style E fill:#4CAF50,stroke:#2E7D32 style F fill:#2196F3,stroke:#1565C0
4. 部署复杂度对比
vLLM多卡部署流程
1 2 3 4 5 6 torchrun --nproc_per_node 4 --master_port 29500 \ vllm.entrypoints.api_server \ --model deepseek-r1-32b \ --tensor-parallel-size 4 \ --block-size 64
Ollama单卡部署
1 2 3 ollama create deepseek-r1 -f Modelfile ollama run deepseek-r1 --verbose
5. 功能扩展性对比
功能
vLLMLM
Ollama
API兼容性 完全兼容OpenAI API标准
自定义REST API
监控指标 提供Prometheus格式metrics
仅基础日志输出
热更新支持 支持模型热切换
需重启服务
流量控制 内置QoS策略引擎
依赖外部网关
6. 迁移成本分析
迁移方向
代码改动量
性能收益
风险等级
Ollama → vLLM
高(60%)
300% QPS提升
⚠️⚠️⚠️
vLLM → Ollama
低(20%)
功能降级
⚠️⚠️